I started with NetBSD in the mid-nineties, on a Sun SPARC ELC with 32Mbyte of memory, where I used GCC and Emacs on X11 with FVWM as the window manager. I'm still using GCC, Emacs, and FVWM with the same configuration files (updated for pointless changes in Emacs and FVWM), but I now need much more memory and CPU performance... I thought it would be interesting to investigate why.
Much of this is likely due to GCC — the GCC 2.7.2
There is a script
Cross-compiling individual components are also trivial. The tools are per default placed in a directory named after the host platform, in my case
Much of this is likely due to GCC — the GCC 2.7.2
cc1 from NetBSD 1.2 has a text segment size of 1073152 bytes, while GCC 4.8.5 used for today's NetBSD has a size of 11012557, and I believe the dynamic memory and instruction count used during compilation has increased much more than that. But the operating system has also increased in size (for example, NetBSD 1.2 libc.so is 331776 bytes, compared to 1390980 today), and I plan to start my investigation by looking at the OS.Building NetBSD
One thing I like about NetBSD is that it avoids pointless changes, so the build process has been the same for a long time. In addition, is is easy to cross-compile it for different architectures — in fact, NetBSD is always cross-compiled, even when building e.g. a x86 distribution on a x86 architecture.There is a script
build.sh that sets up everything, so building a release for e.g. Sun SPARC can be done as
./build.sh -u -U -m sparc releaseThis first compiles the tools needed for the build, then builds the full release of NetBSD, and packages the result. This works on "any" operating system — you can build NetBSD on e.g. Linux and Mac OS X.
Cross-compiling individual components are also trivial. The tools are per default placed in a directory named after the host platform, in my case
obj/tooldir.NetBSD-6.1.5-i386/bin. The most useful tool here is a wrapper for make that sets up the environment for cross-compiling. This can be used to compile any component, e.g.cd lib/libc ../../obj/tooldir.NetBSD-6.1.5-i386/bin/nbmake-sparcwill build
libc.so.Some results
As a first step, I have built a NetBSD release from trunk 1 January each year 2002–2016, mostly just in order to see that it was as easy to build as I thought, and to try to get a feel for what can be interesting to investigate closer. I stopped at 2002, as thebuild.sh was not available earlier...I built i386 (which is the NetBSD name for x86, even though it does not support i386 CPUs any longer) and sun3. The reason I choose them is that they represent two extremes of architectures — sun3 is a hardware platform that was obsolete already in the mid-nineties, so software size "should not" increase for it unless new functionality is added, while the i386 hardware is still used, and it has got more features, bigger caches etc., during this time, which may increase code size.
And the code size has increased during this time. For example, this is how
libc.so, libm.so, and the kernel have grown:
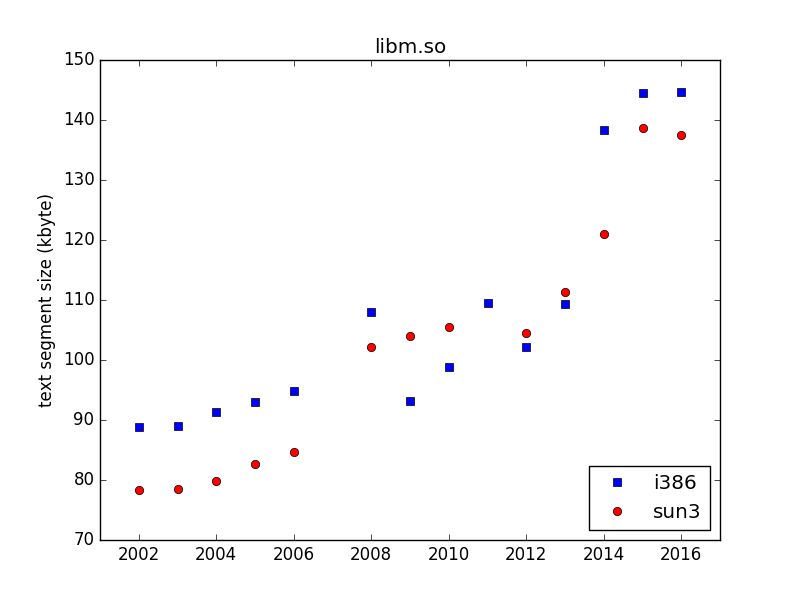

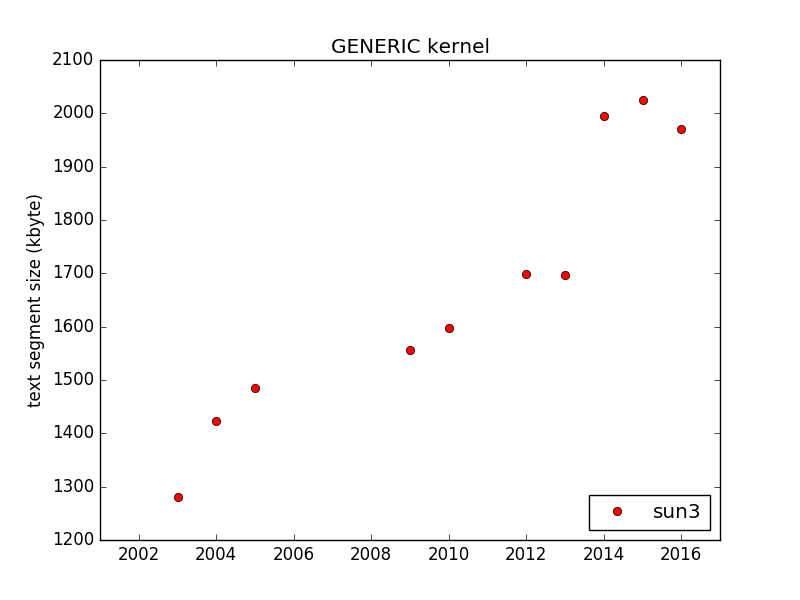
These plots do not say much, and code increase is not necessarily "bad", even on constrained platforms, if unused functionality never get paged in. My plan is to look into the details of the reason for these increases (such as new functionality, support for more hardware, compiler changes, careless developers, etc.), to get a feel for how much each reason contributes. Please let me know if there are some specific questions you want me to investigate!